注意:
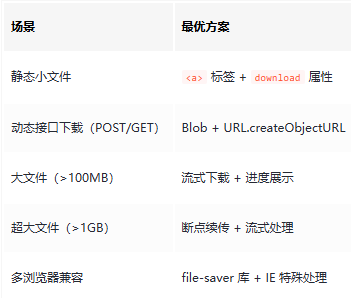
2. 动态接口下载(POST/GET 请求,如导出 Excel)
核心流程:请求接口获取二进制流 → 转 Blob → 生成临时 URL → 触发下载 → 释放 URL。
// 通用下载函数(基于fetch)
async function downloadFile(url, options = {}) {
const {
method = 'GET',
data,
fileName = 'download',
headers = {}
} = options;
try {
// 1. 请求接口,获取二进制响应
const response = await fetch(url, {
method,
headers: {
'Content-Type': 'application/json', // 根据接口调整
...headers
},
body: method === 'POST' ? JSON.stringify(data) : undefined
});
if (!response.ok) throw new Error(`请求失败:${response.status}`);
// 2. 解析为Blob(根据文件类型指定MIME)
const blob = await response.blob();
// 可选:从响应头提取文件名(后端需返回Content-Disposition)
const disposition = response.headers.get('Content-Disposition');
if (disposition) {
const match = disposition.match(/filename="?([^";]+)"?/);
if (match) fileName = decodeURIComponent(match[1]);
}
// 3. 生成临时URL并触发下载
const blobUrl = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = blobUrl;
a.download = fileName; // 文件名(含扩展名)
a.click();
// 4. 释放内存(关键)
URL.revokeObjectURL(blobUrl);
return { success: true };
} catch (error) {
console.error('下载失败:', error);
return { success: false, error };
}
}
// 调用示例:导出Excel(POST请求)
downloadFile('/api/export/excel', {
method: 'POST',
data: { startDate: '2025-01-01', endDate: '2025-12-31' },
fileName: '2025数据报表.xlsx'
}).then(res => {
if (res.success) alert('下载成功');
else alert('下载失败:' + res.error.message);
});
三、进阶优化方案
1. 大文件下载(流式处理 + 进度展示)
使用 Response.body 流式读取,避免一次性加载大文件到内存:
async function downloadLargeFile(url, fileName) {
const response = await fetch(url);
if (!response.ok) throw new Error('请求失败');
// 获取文件总大小
const totalSize = Number(response.headers.get('Content-Length'));
let downloadedSize = 0;
// 流式读取响应
const reader = response.body.getReader();
const chunks = [];
while (true) {
const { done, value } = await reader.read();
if (done) break;
chunks.push(value);
downloadedSize += value.length;
// 计算进度(展示给用户)
const progress = (downloadedSize / totalSize) * 100;
console.log(`下载进度:${progress.toFixed(2)}%`);
}
// 合并分块为Blob
const blob = new Blob(chunks);
// 后续同普通Blob下载逻辑...
}
2. 断点续传(基于 Range 请求)
适用于超大文件,核心是后端支持 Range 头,前端记录已下载的字节范围:
// 断点续传核心逻辑
async function resumeDownload(url, fileName, startByte = 0) {
const response = await fetch(url, {
headers: {
Range: `bytes=${startByte}-` // 请求从startByte开始的字节
}
});
// 后端返回206 Partial Content表示支持续传
if (response.status !== 206) throw new Error('不支持断点续传');
// 读取剩余字节并追加到已下载的Blob中(需本地存储已下载的块)
// (完整实现需结合localStorage/indexedDB存储已下载块和进度)
}
3. 兼容性处理
// 兼容IE的Blob下载
function downloadBlobIE(blob, fileName) {
if (window.navigator.msSaveBlob) {
window.navigator.msSaveBlob(blob, fileName);
} else {
// 普通浏览器逻辑
}
}
4. 后端配合最佳实践
前端下载的稳定性依赖后端配置,需要求后端:
返回正确的 Content-Type(如 application/vnd.openxmlformats-officedocument.spreadsheetml.sheet 对应 xlsx);
设置 Content-Disposition 头:attachment; filename="文件名.xlsx"(解决文件名乱码);
跨域场景配置 Access-Control-Expose-Headers: Content-Disposition, Content-Length(让前端能读取这些头);
大文件支持 Range 请求(断点续传);
设置合理的 Content-Length(便于前端计算进度)。
四、避坑指南
1.文件名乱码:
2.Blob 内存泄漏:务必调用 URL.revokeObjectURL 释放临时 URL。
3.跨域下载失败:
4.文件类型错误:确保 Blob 的 MIME 类型与文件扩展名匹配(如 xlsx 对应application/vnd.openxmlformats-officedocument.spreadsheetml.sheet)。
五、推荐工具库
import { saveAs } from 'file-saver';
saveAs(blob, '文件名.xlsx');
总结
核心原则:优先使用原生能力,复杂场景封装通用函数,大文件关注内存和进度,跨域依赖后端配置。
参考文章:原文链接






 400 186 1886
400 186 1886



