当你和大模型对话时,模型在做什么
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
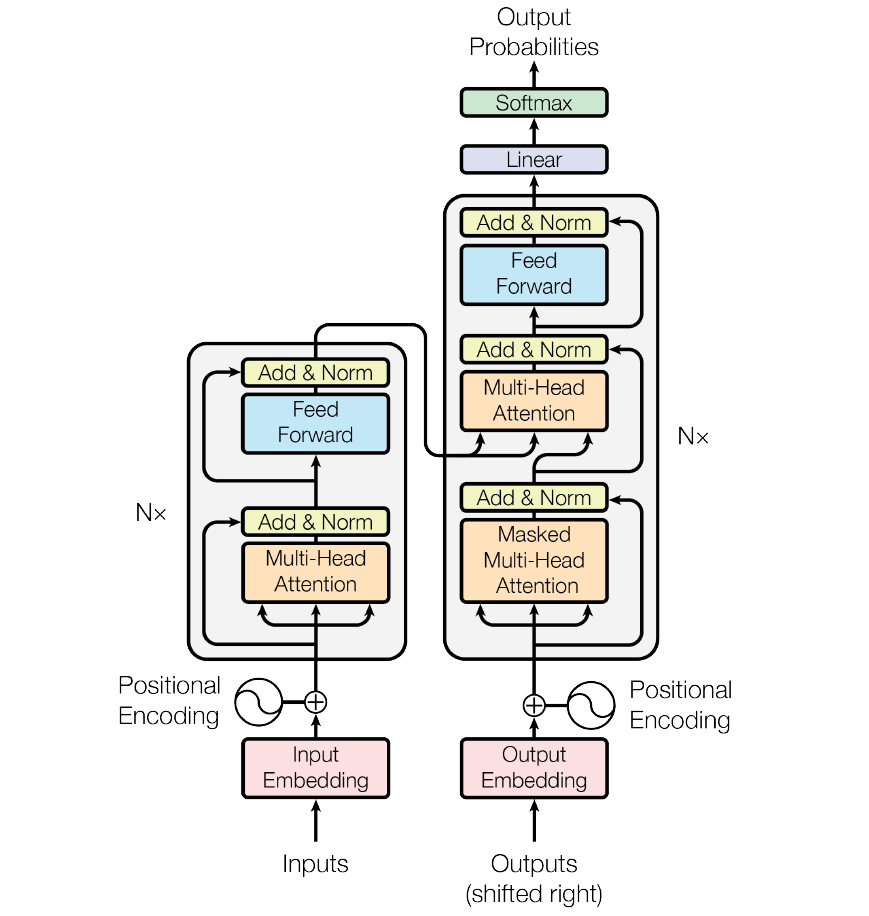
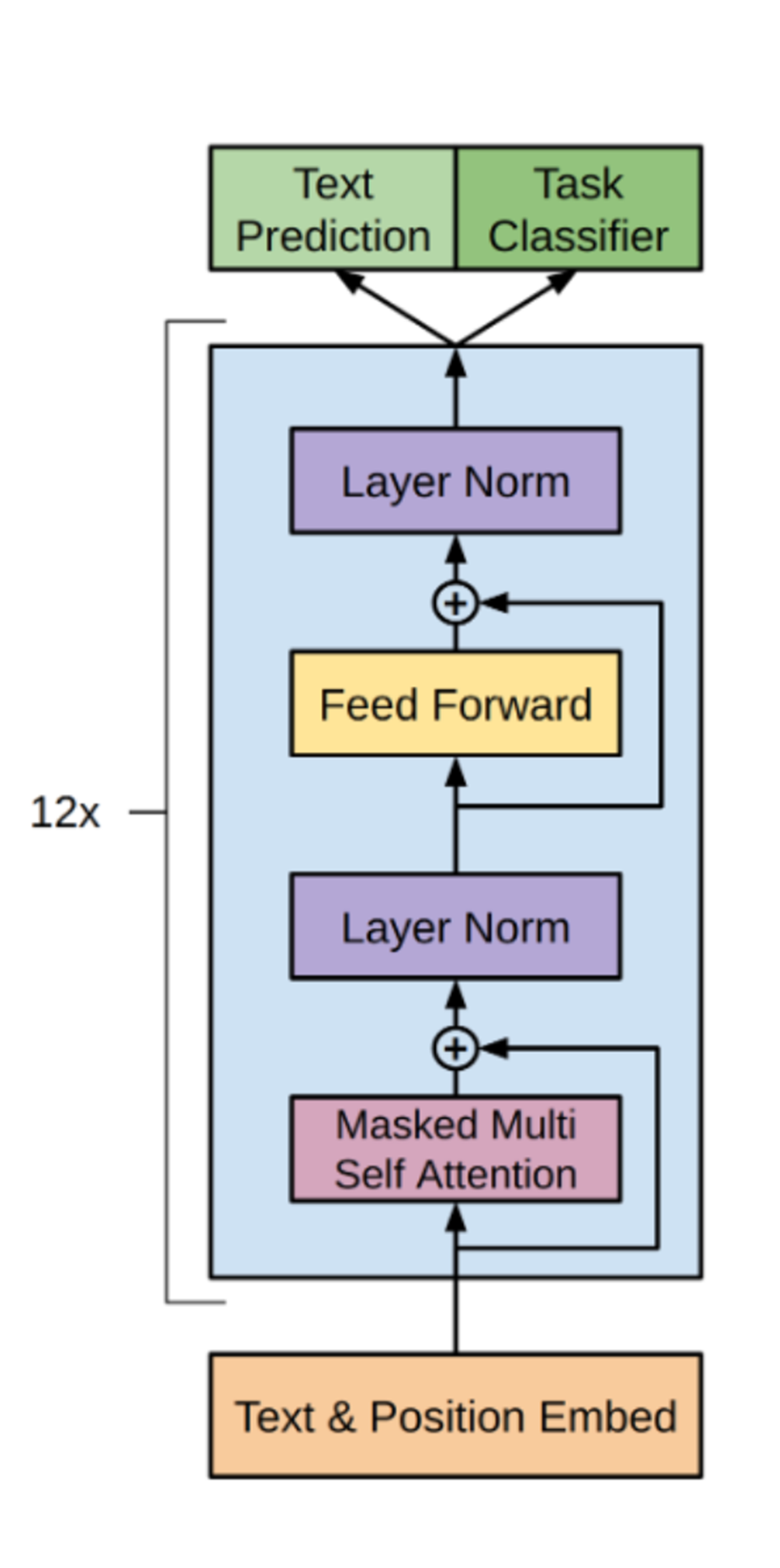
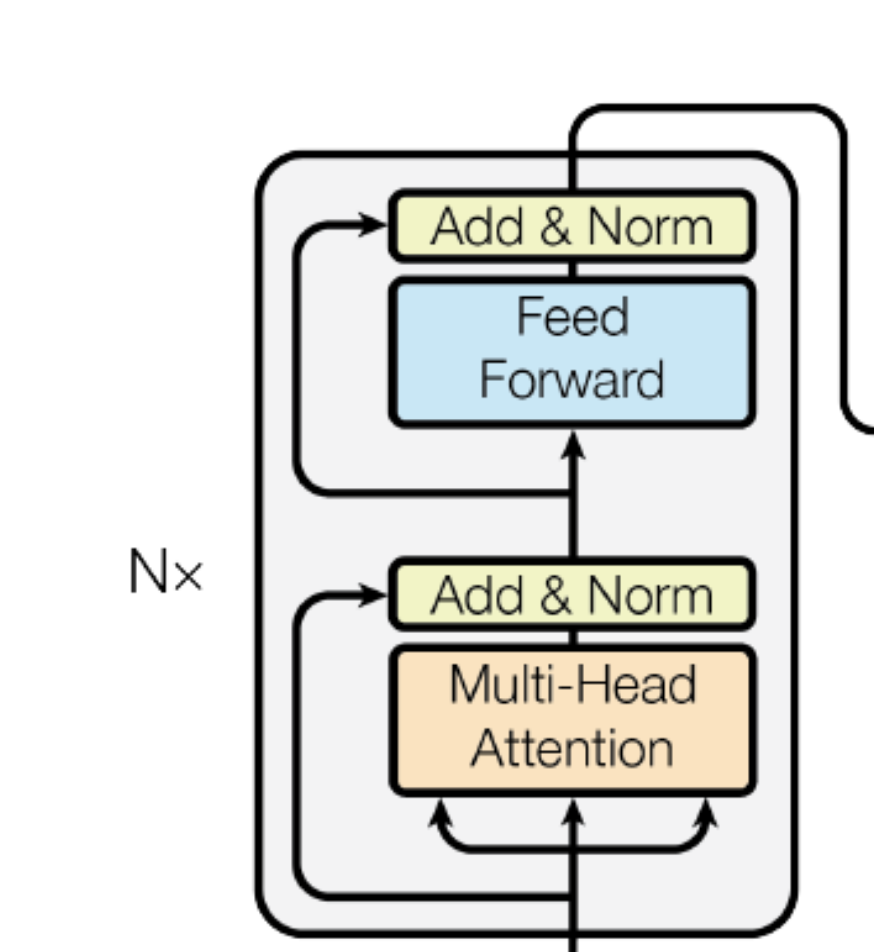
简介:你可能每天都在跟ChatGPT这样的人工智能聊天,向它提出各种问题,或与它讨论各种话题。那么,当你敲下一句问题时,大模型究竟是怎么运行的,如何能一个字一个字输出正确的回答?大模型并不是黑盒,本文会从模型生成答案的过程来解释下Transformer的结构以及模型是如何进行推理的,希望能给大家建立一个大致认知。 为什么要了解模型的推理过程? 作为应用层开发人员,日常更多是做工程上的实践和模型底层技术并没有太多交集。个人体会在理解底层原理后,是能帮我们建立更好的直觉,日常在做各种技术决策时能帮我更好判断这个需求能不能做?能做到什么程度?用哪种方案更合适?当然你也可以每次决策都去问ChatGPT,但是这样效率低,而且ChatGPT给出的结果也不是全对,还需要自己判断取舍。所以了解模型的底层原理是很有必要的。 为什么叫大模型?因为参数量很大。大模型在回答问题时,总是一个字一个字的输出,所以大模型也叫生成AI。 大模型就像一个巨大的函数,在回答问题时,会根据输入和已经输出的内容,不停的预测下个单词,一直到回答结束,就像词语接龙一样。 Transformer介绍Transformer本质是指一种神经网络结构,它的计算核心由多个重复堆叠的模块组成,每个模块都包含多头注意力和前馈网络,并通过残差链接与层归一化相衔接。
Transformer有三种常用的结构:
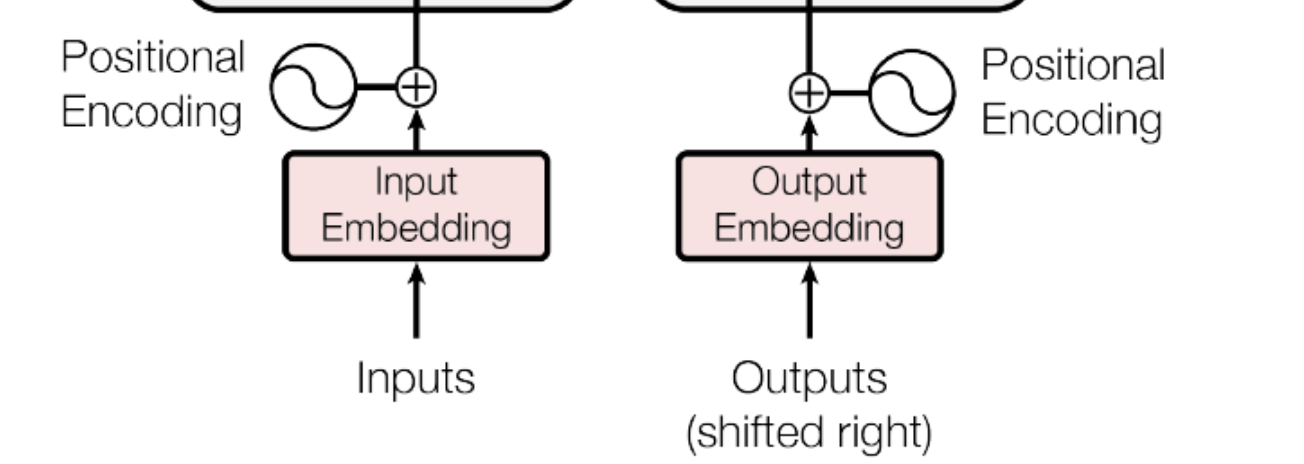
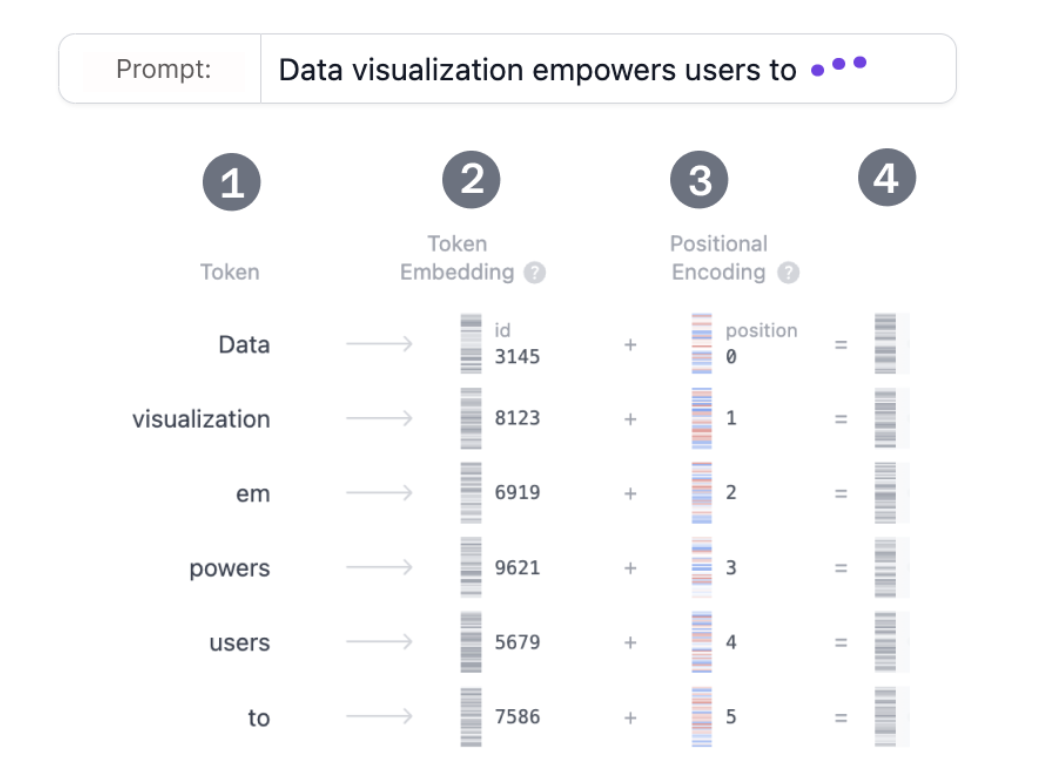
模型运行的第一步embedding当我们输入“世界上最高的山峰是哪座?”,模型首先会把用户的输入做分词处理,这个分词方式每个模型都不太一样,主流的方法有三种:BPE、WordPiece、Unigram。 下图是一个分词示例:
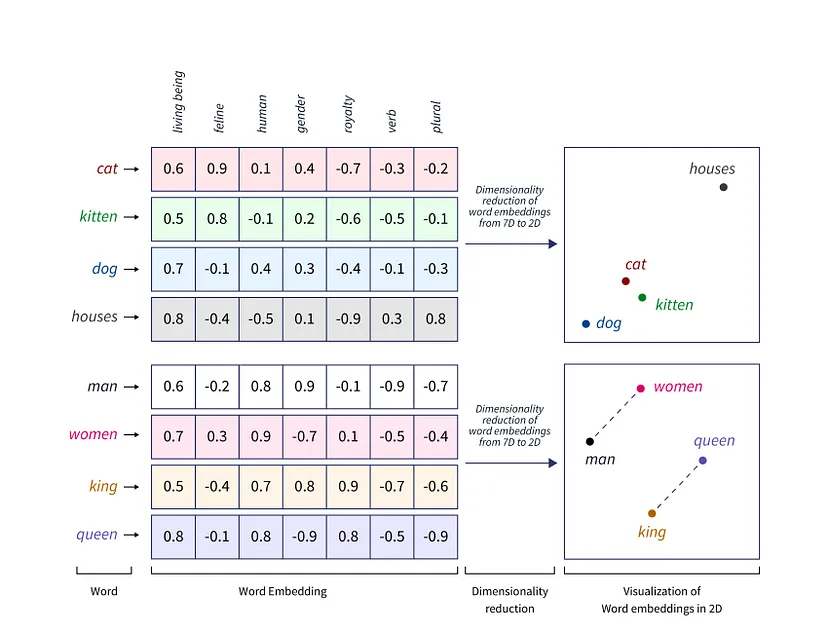
如图可以看到一个完整的提问被分成6个词,拿到分词结果后会根据已经训练好的词表,找到词的对应向量信息,这个过程类似于查字典,找到每个词的含义,最后再加上词的位置信息,结合词的位置信息可以让模型更好的解释词在句子中含义。 词向量是表示自然语言里单词的一种方法,会把每个词都表示为高维空间的向量。通过这种方法,实现把自然语言计算转换为向量计算。同时每个词对应什么向量也是通过模型训练得到的。有一个经典的通过向量对自然语言计算的案例,queen = king - man + women。如下图: 模型运行的第二步:Encoding拿到词向量加上位置编码信息后,下一步就是Encoding的过程。
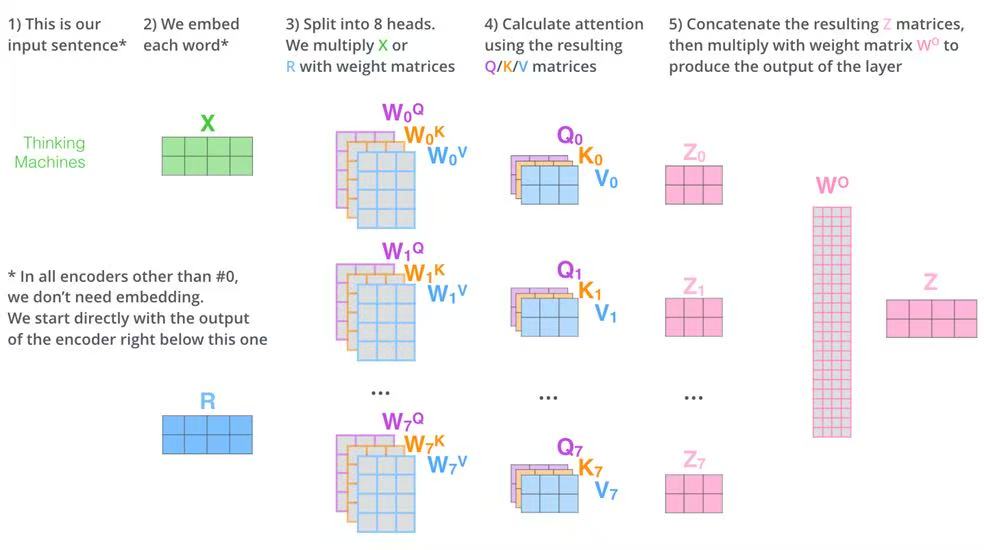
Multi-Head Attention通过前面的步骤,每个token的向量只包含自己的含义和位置信息,如果我们类比下自己的语言就知道,一句话的实际含义并不能只看每个字的含义,你还需要结合上下文来看,在不同的上下文中,它的含义可能完全不同,比如:模,在大模型中代表算法模型,在模特中代表一种职业。Multi-Head Attention就是要把token放在整个上下文中来计算它的真实含义。 Multi-Head Attention是由多个自注意力机制(self attention)组成,所以我们先学习下自注意力机制。
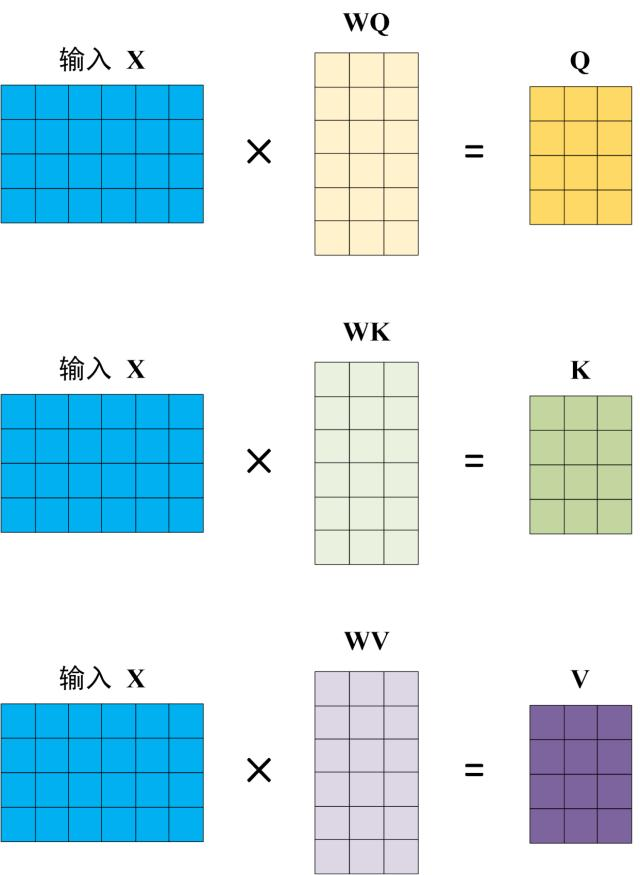
WQ WK WV这三个矩阵是事先训练好的三个参数矩阵也是大模型参数的一部分,以GPT3为例,WQ WK WV的大小都是12288*12288=151M个参数 把输入分别乘以WQ WK WV之后,就得到了Q K V三个矩阵,矩阵的每一行仍然对应一个token,只是乘上了不同的矩阵,向量值不一样。 后续举证的详细计算过程如下图:
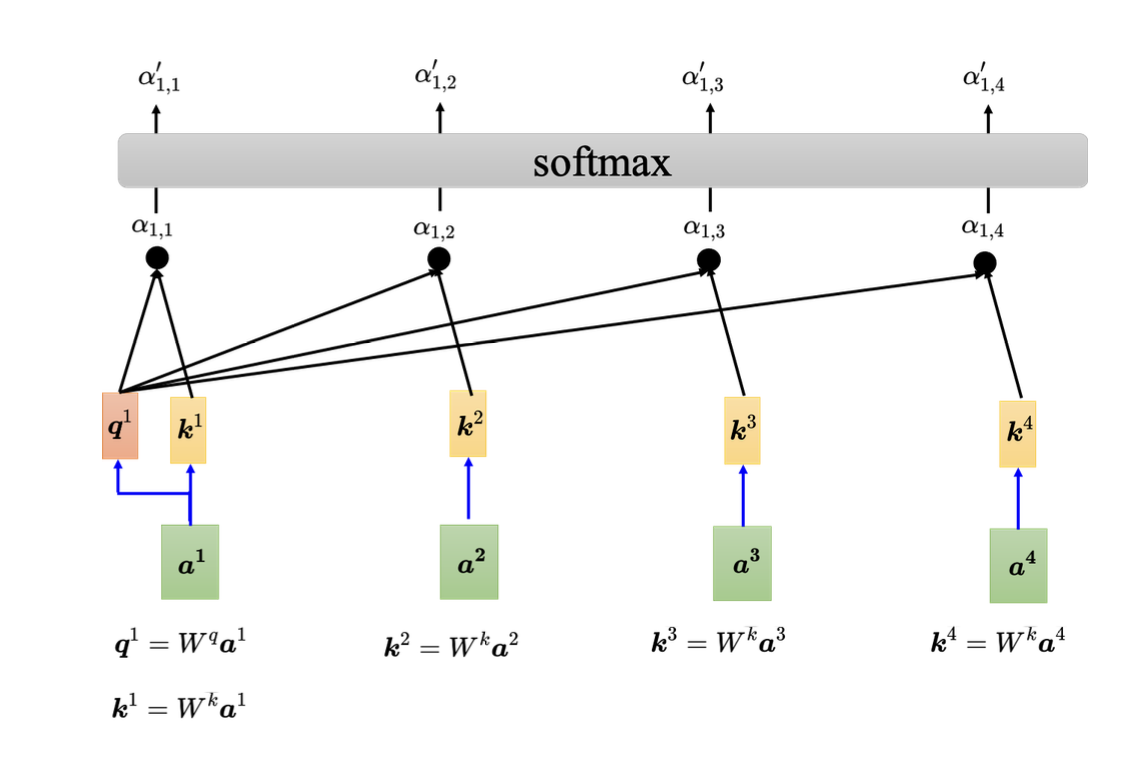
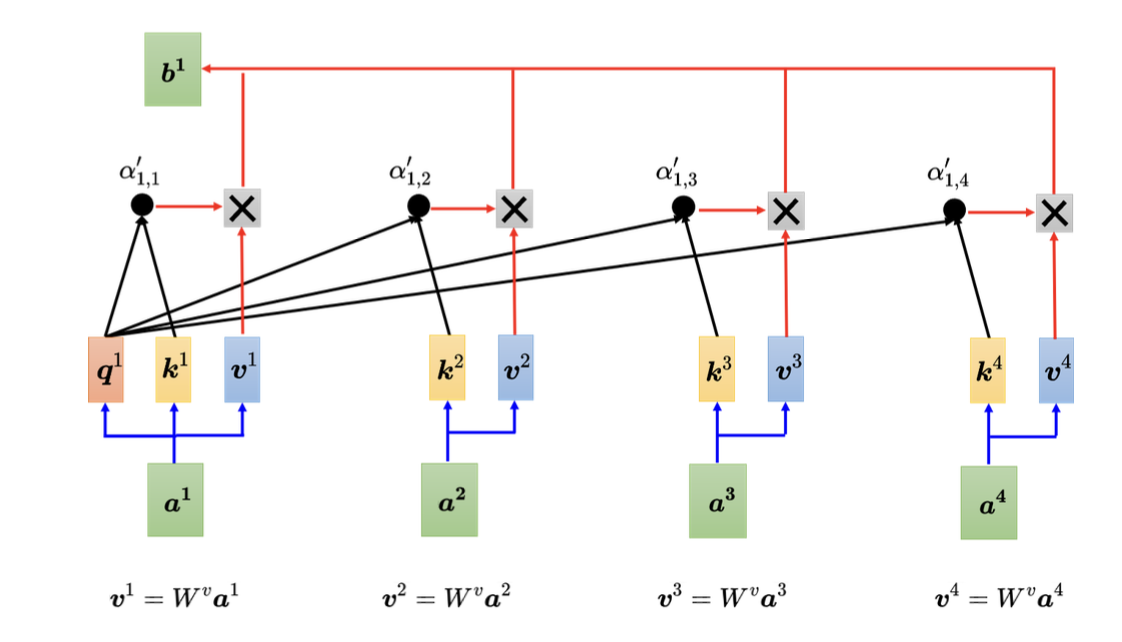
下图表示a1向量经过自注意力变换后得到b1的过程:
看了上面的计算过程,可以知道经过Q K V三个矩阵的运算,最后每个token的输出向量都是加入了其他token的向量计算,也就是考虑到了其他token,也就是上下文! 了解了自注意机制,多头注意力就是把上面的计算过程拆分为了多个矩阵计算,最后再做合并的过程,计算过程如下:
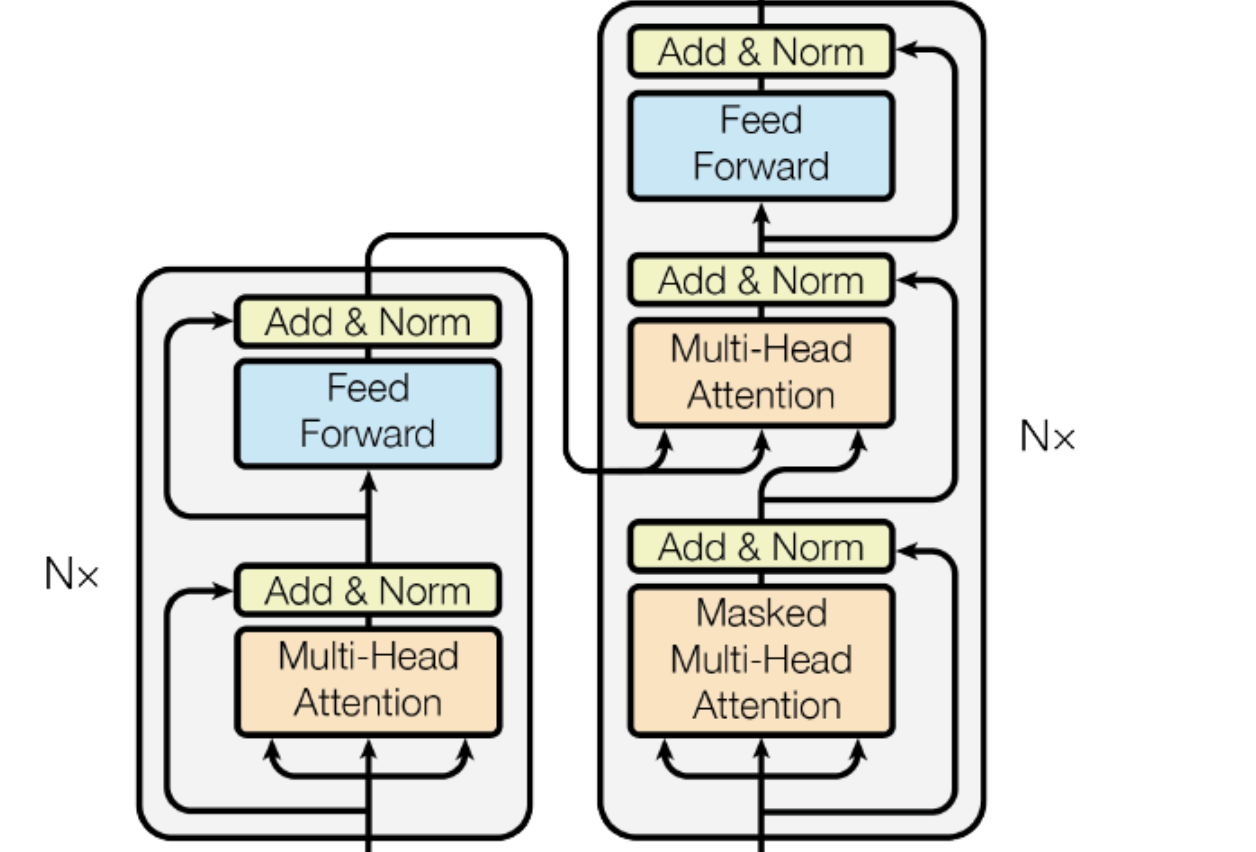
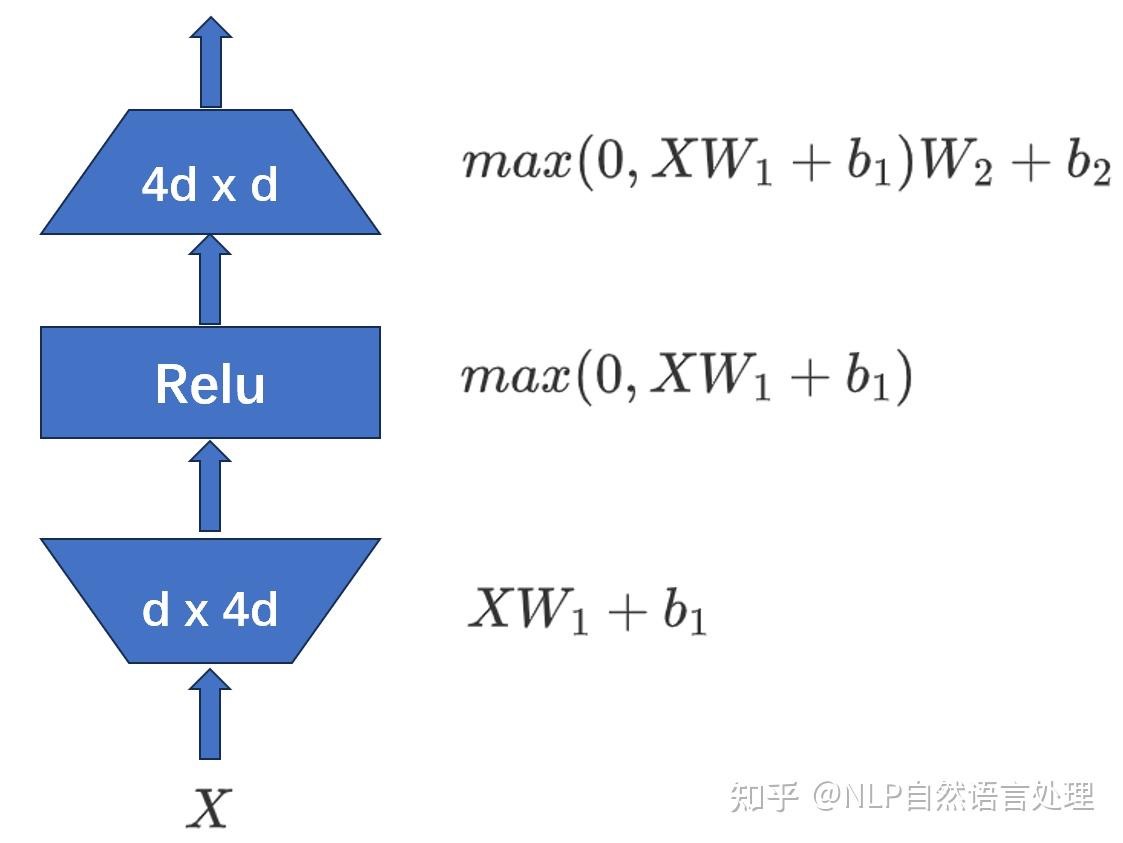
这四个矩阵加起来的参数量*96(96个头)等于57.98B约占总参数量(175B)的33%。 Add& NormAdd 是残差链接(Residual Connection):这里是为了缓解梯度消失/爆炸、信息保真(子层学不到东西时,模型可以退变差化为恒等映射,性能不会)、收敛更快。可以注意的点是,这里的计算过程不仅用了自注意计算的向量,还用了token的原始向量。 Norm 是层归一化(Layer Normalization):稳定激活分布(把每个token按均值0、方差1归一化,防止层与层之间数值飘逸) Feed Forward详细的逻辑图如下:
非线性激活函数:经过生维线性变换后,输入会通过一个激活函数,增加模型的非线性表达能力。常用的激活函数包括ReLU、Sigmoid、Tanh等,顺便说一下,当前主流大模型常用的SwiGLU。 降维线性变换:经过激活函数后,再进行一次线性变换,利用降维矩阵将高维空间的特征映射回原始空间,得到FFN层的输出。 模型运行第三步:Decoding
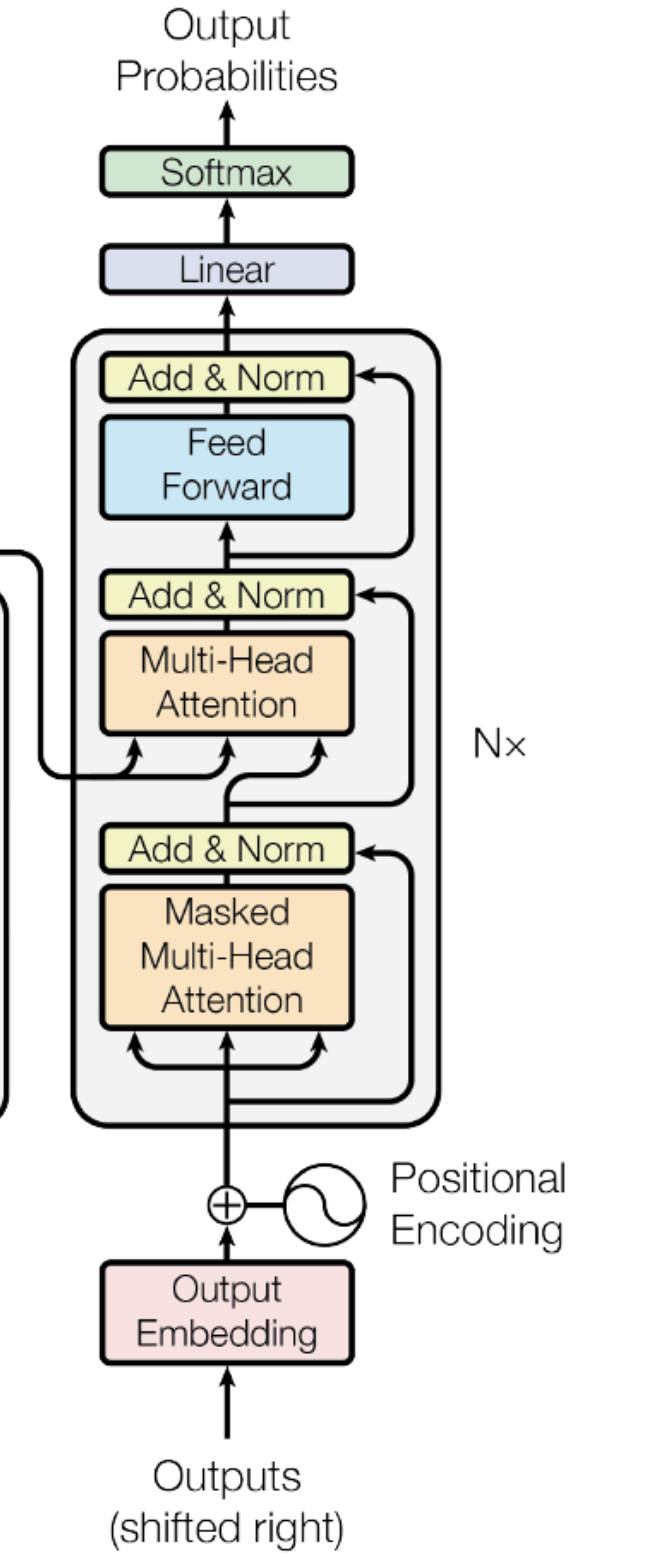
解码器结构其实和编码器结构很相似。不同点,在于:
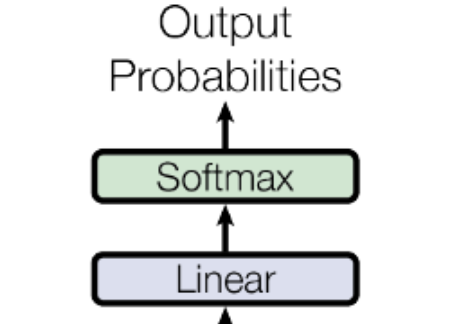
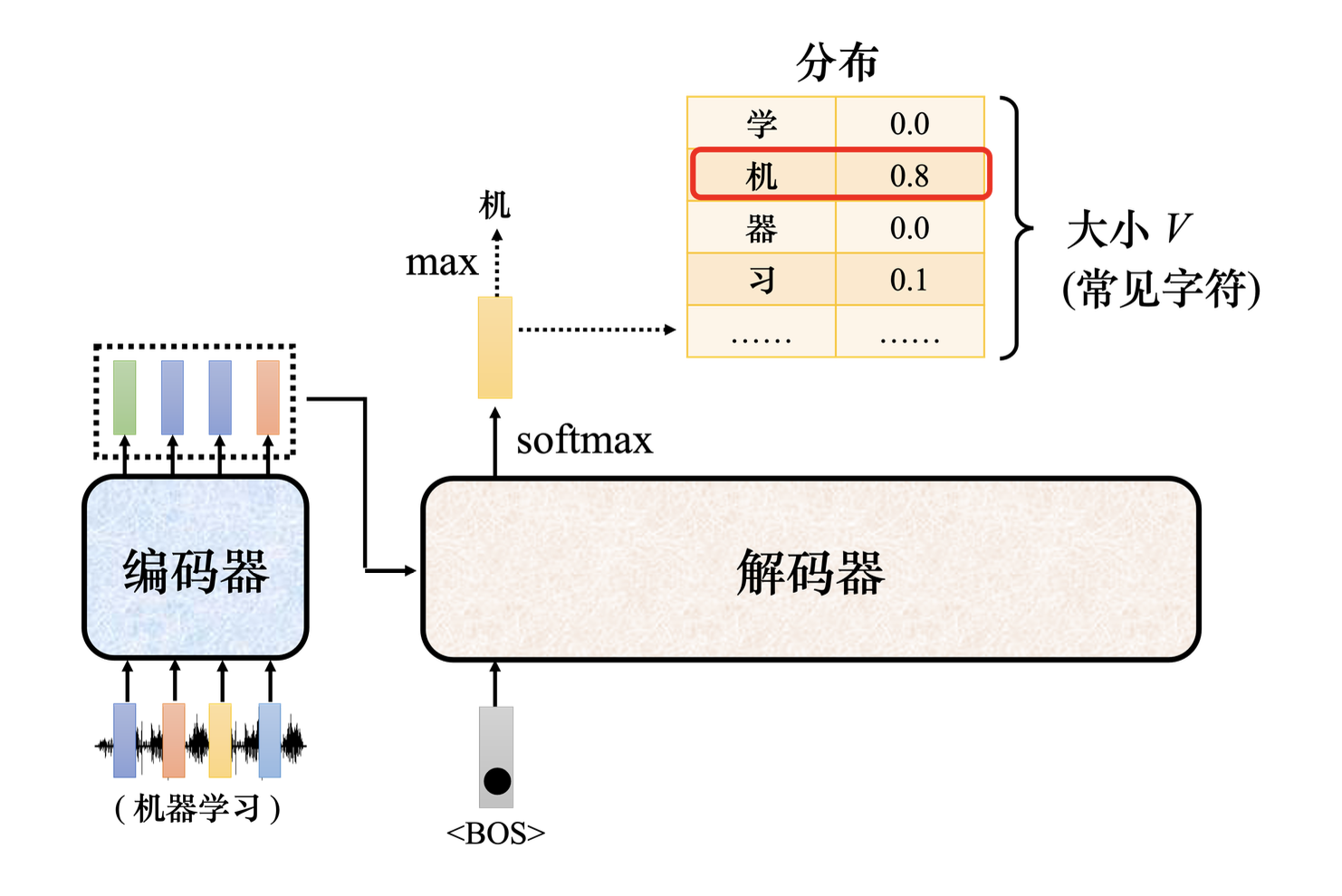
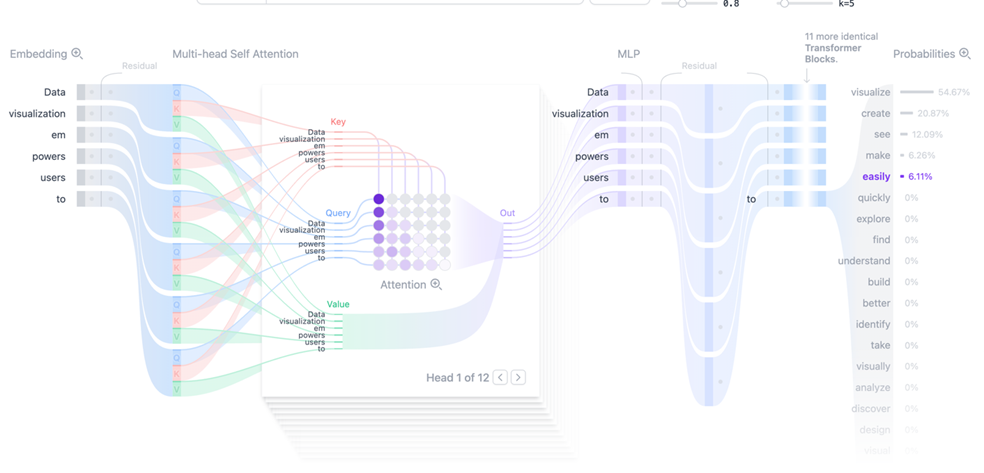
模型运行最后一步:output以上的多次运算后,在最后一个输入的向量中已经包含了整个输入序列的信息,这里显性变换就是为了把最后一个输入向量映射到词表维度上,预测哪一个token的输出概率最高。 X是输入,推理时是最后一个token的向量,维度是[1, d_model]、WT是权重矩阵维度[vocab_size, d_model] 可以看到举证变换后,把最后一个token的向量,变成了词表上每个词的概率分布。 总结由于篇幅限制,本文只是非常粗略的介绍了整个生成过程。同时有还有很多细节我也还没真正理解,比如:为什么自注意机制是有效的?是偶然发现的还是经过精心设计的?等等。 下图是一个完整生成过程图(Decoder-Only结构),可以参考帮助理解。 转自https://www.cnblogs.com/ekoeko/p/19295509 该文章在 2025/12/3 15:42:58 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886