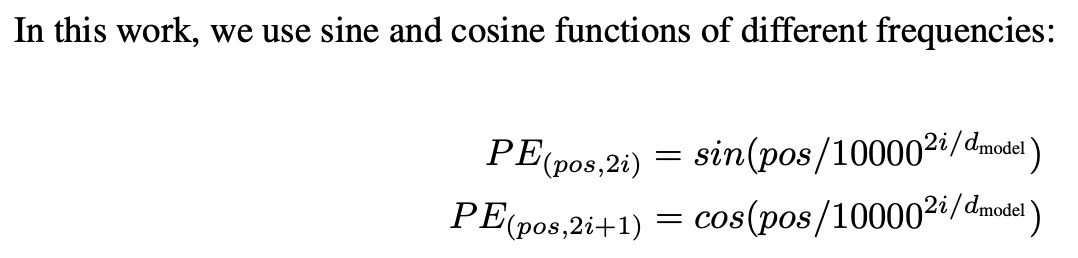一文搞懂 LLM 的 Transformer!看完能和别人吹一年
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
如果你想对当下 AI LLM(大语言模型) 的工作原理有所了解,揭开 ChatGPT、DeepSeek 背后的秘密,那一定要认识一下本文的主角 Transformer。 当提起 Transformer 这个话题时,仿佛人人都可以讲些相关名词出来,什么自注意力机制啊、encoder、decoder什么的,但若深入追问细节,却很少有人能真正地说清楚。 它最初来自一篇被称为“AI 大航海时代起点”的论文:
这篇论文首次提出的 Transformer 架构,已经成为当下所有大模型的基础。 今天我们就从这篇最初的论文出发,真正理解下 Transformer 究竟是何方神圣。 本文不讨论公式,只解读图表,旨在让更多读者看完就能通俗地、成体系地给身边其他人讲清楚 Transformer 工作原理,从而真正理解它究竟为什么如此火爆。 首先,先引用这篇论文中的关于 Transformer 这个模型的整体架构图:
上来直接就看架构图是不是有些晕? 没关系,下面我们就来一步步通俗理解下这张架构图的深层含义。 图的左边一侧Input(输入),整体代表Encoder;右边一侧Output(输出),整体代表Decoder。 01|输入是怎么被 Transformer“看懂”的?整个输入流程你只需要先记住下面的关键流程:
然后我们来一点一点看。 ① Input Embedding:把词变成数字向量模型不认识“我”、“你”、“猫”这些词,只能接受数字。 所以,需要把每个词转换成一个向量,也就是一组数字,例如:
这里简化了精度方便阅读,向量化这一步非常基础,但也是理解后面一切的起点。 ② Positional Encoding:给模型装上“位置感”Transformer 没有像传统 RNN 那样按顺序逐词处理输入,因此模型本身无法“天然”感知词的先后关系。 所以需要额外告诉模型:
论文使用了 sin + cos 函数计算的位置编码方式,让每个词清楚自己的“位置”。
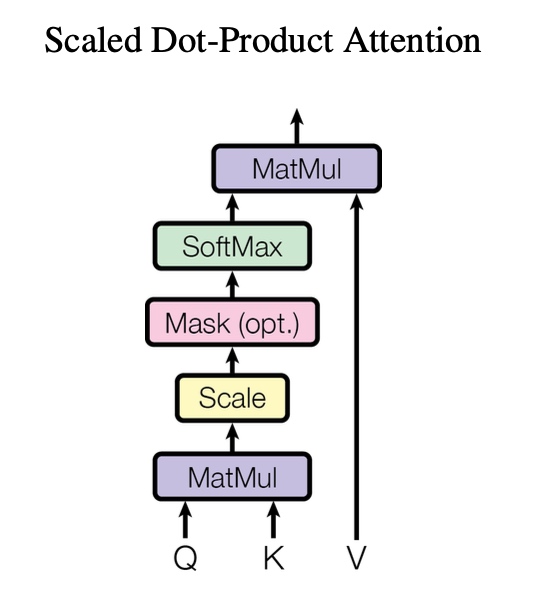
sin/cos 位置编码乍一看有点数学味,但对模型来说是非常简单高效的。 它像给每个位置贴上一段独一无二的“节奏标签”,让 Transformer 能分辨词的“位置”,同时又不需要多余的训练成本。 ③ Q / K / V:Self-Attention 的灵魂这是最让人拍案叫绝的设计之一。
句子中的每个词都会生成 3 个向量:
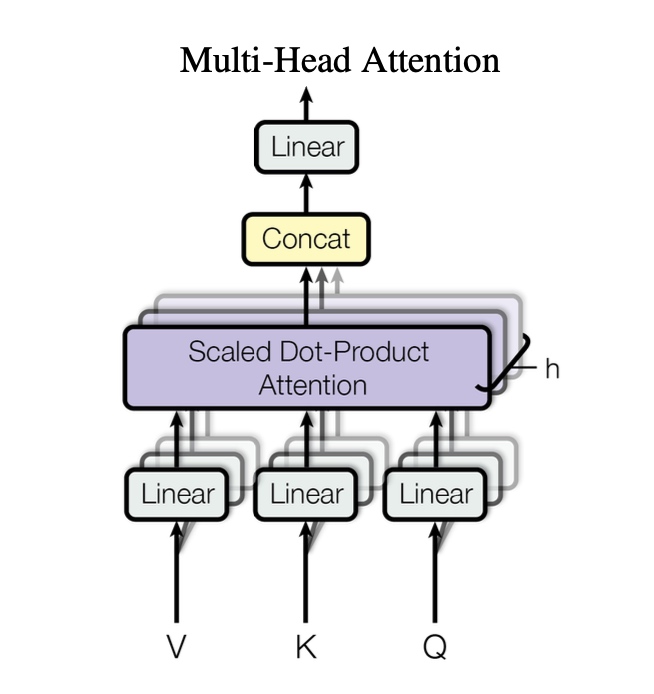
它们不是概念,而是实实在在的矩阵乘法结果。 接下来,句子里的每个词都会: 拿着自己的 Q 到其他词的 K 那里去“打分”,问: 打分越高,就越关注这个词。 最后对 V 进行加权求和,得到“新含义”。 这就是单一的 Self-Attention。 02|为什么需要 Multi-Head Attention?有了单一的 Self-Attention,为啥又需要 Multi-Head Attention 呢? 因为我们需要从多个角度来理解自然语言。
注意力头的数量是一个超参(Hyperparameter),每个注意力头可以关注不同的视角,例如:
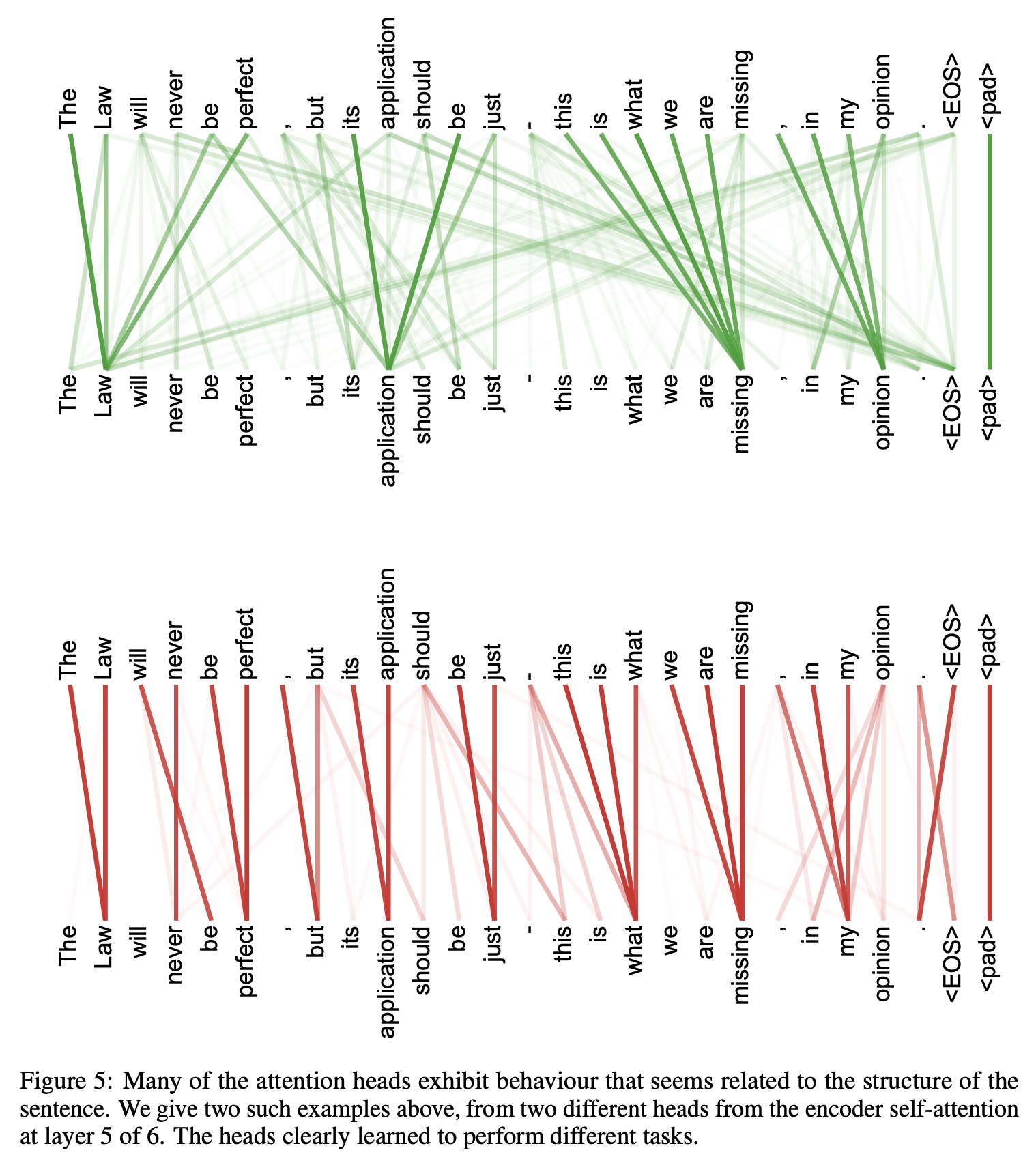
Transformer 不是只看一个角度,论文中的例子是并行开 8 个注意力头。 实际可以开12 个、48 个甚至更多的注意力头,从更多视角扫描句子。 下图是论文最后给出的一个简单示例,描述了针对同一段文字,两个不同的注意力头所展现出的各自关系,可以看到确实存在明显区别:
这就是 Multi-Head Attention 的直观体现。 03|残差连接 + LayerNorm:让训练更稳定Self-Attention 只是“加工”了一遍词向量,但我们肯定还不能丢掉原始信息。 于是: 原始输入 + 注意力结果 → 做 LayerNorm 归一化(对应架构图中 Add & Norm) 这个残差结构让训练稳定得多,也能堆更多层。 04|Feed Forward 网络(FFN):进一步加工语义Attention层负责广撒网,把相关信息搜集到一起; FFN则负责深加工,对这个信息进行更复杂、更深度的非线性变换。 又晕了?其实通俗来讲就是:Attention 负责找关系,FFN 负责提升表达力。 论文中描述FFN的关键内容参考如下:
简单理解它就是一个非常朴素的两层全连接网络:
FFN 的结果是:让每个 token 得到更丰富、更抽象的特征表达,这样模型才能表达更复杂的模式,而不仅仅是做简单的线性组合。 05|重复 N 次:论文是 6 层,可以加更多论文里 Encoder 但这其实也是一个 超参(Hyperparameter)。 后来的 BERT、GPT、Llama 都堆到了几十层甚至上百层。 一般来讲,层数越多、模型越大、理解力越强。 这其实也是模型训练堆GPU能“大力出奇迹”的理论基础。 06|Decoder 如何像人一样“输出”内容?Decoder是模型的“写作器”,其工作严格遵循架构图右侧流程,核心是 “从左到右,逐词生成”。 为了理解这个过程,我们以翻译任务为例:输入 "I Love You",输出 "我爱你"。 ① Output Embedding:先把输出词变向量理解方式和输入一样,每个词被映射成一个向量,用于后续计算。 ② Shifted Right:防止模型“偷看答案”在模型训练阶段,需要把标准答案整体右移一位,并在开头加上起始符 此时模型看到的是: 也就是右移一格。 ③ Masked Multi-Head Attention:遮住未来有同学说了,上面向右移一位没啥意义呀,模型还是可以看到答案的一部分,直接抄就可以啊,起不到训练效果。 此时就需要 也就是说它和上面的 比如模型要开始做这张填空卷了。它需要依次填出三个空: ④ Multi-Head Attention- “请教Encoder”Decoder 在生成新词时,需要参考 Encoder 的输出。这层 Attention 是桥梁,连接输入和输出,让 Decoder 可以“请教 Encoder”: “你生成的词和输入序列的哪些部分相关?” 例如翻译 "I Love You":
⑤ Linear + Softmax:得到下一个词的概率比如已经生成了“我爱”,后面这个字是啥,会有类似这样的一组概率:
选概率最高的,就是下一个要生成的词。 最终总结通过本文的讲解,我们一步步拆解了Transformer的核心机制:从词向量化与位置编码奠定基础,到Self-Attention与Multi-Head Attention实现多视角的语义捕捉,再通过残差连接与LayerNorm保障训练的稳定性,最后由FFN进行深度非线性变换以增强特征表达。 Encoder通过堆叠N个相同的层来逐步深化对输入的理解;Decoder的每个层则严格遵循一个更复杂的处理流程: 在Masked Multi-Head Attention中确保生成时不会“偷看”未来,并经过Add & Norm。 在Multi-Head Attention(即论文中的Encoder-Decoder Attention层)中“请教”Encoder的最终输出,并再次经过Add & Norm。 同样通过一个FFN网络进行深度加工,并最终经过Add & Norm后输出给下一层或最终的预测模块。 最终,Decoder的输出经由Linear+Softmax层转换为下一个词的概率分布。Transformer凭借这一高度并行、可扩展的对称性设计(Encoder与Decoder层具有相似的核心结构),成为当今所有大语言模型的基石,完美诠释了 转自https://www.cnblogs.com/jyzhao/p/19275222/ 该文章在 2025/12/5 9:24:56 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886