MySQL 中 count(*)、count(1)、count(字段)性能对比:一次彻底搞清楚
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
团队 code review 时,一位同事把 count(*)改成了 count(1),说这样性能更好。真的是这样吗?今天通过源码和实测数据,把这个问题说透。
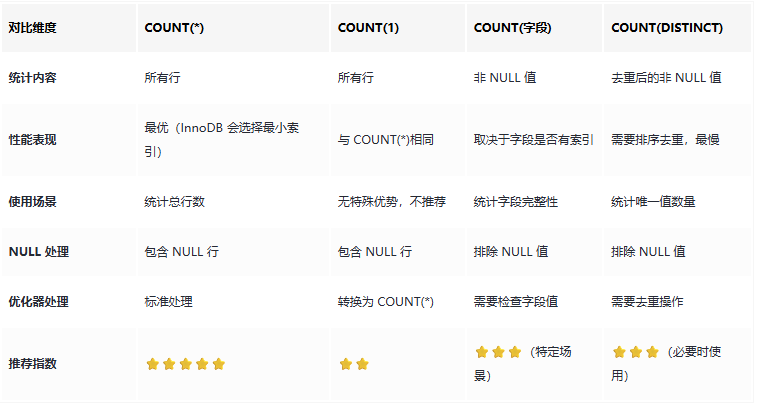
三种 count 方式的本质区别先看看这三种写法在 MySQL 中到底做了什么: 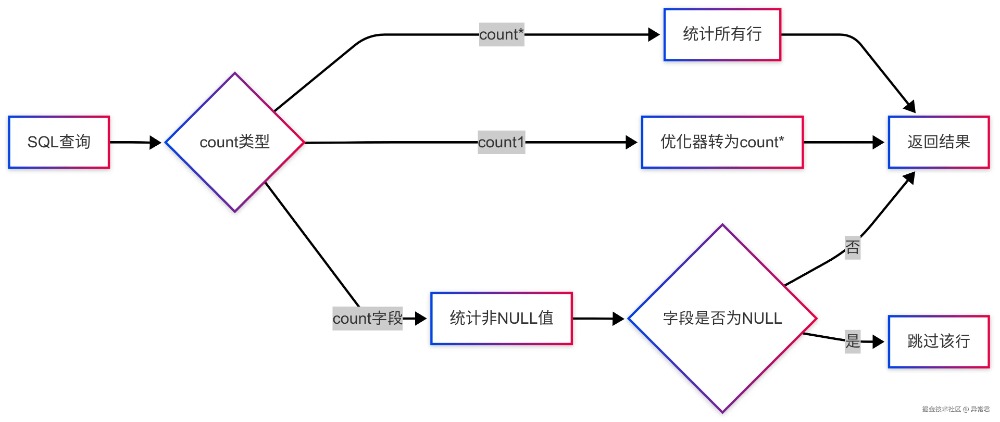 性能测试:用数据说话创建测试环境,准备 1000 万条数据,多轮测试取平均值: 基准测试结果(基于 AWS RDS MySQL 8.0.28)测试环境:
结论:COUNT(*)和 COUNT(1)性能基本一致,COUNT(非索引列)性能最差。 存储引擎差异与索引统计不同存储引擎对 COUNT 的处理方式差异很大:
执行计划成本分析与监控通过 EXPLAIN 和性能监控深入分析 COUNT 的执行成本: 代码高亮: @Component @Slf4j public class CountCostAnalyzer { @Autowired private JdbcTemplate jdbcTemplate; @Autowired private MeterRegistry meterRegistry; public void analyzeCountPlans() { String[] queries = { "SELECT COUNT(*) FROM user_test", "SELECT COUNT(1) FROM user_test", "SELECT COUNT(id) FROM user_test", "SELECT COUNT(username) FROM user_test", "SELECT COUNT(email) FROM user_test" }; for (String query : queries) { analyzeQueryWithMetrics(query); } } private void analyzeQueryWithMetrics(String query) { Timer.Sample sample = Timer.Sample.start(meterRegistry); try { log.info("分析查询: {}", query); // EXPLAIN分析 List<Map<String, Object>> explainResult = jdbcTemplate.queryForList("EXPLAIN " + query); for (Map<String, Object> row : explainResult) { log.info("type: {}, key: {}, rows: {}, Extra: {}", row.get("type"), row.get("key"), row.get("rows"), row.get("Extra") ); } // 使用会话级profiling analyzeCostProfile(query); // 记录成功指标 meterRegistry.counter("mysql.count.success", "query", extractQueryType(query)) .increment(); } catch (Exception e) { log.error("查询分析失败: {}", query, e); meterRegistry.counter("mysql.count.error", "query", extractQueryType(query)) .increment(); } finally { sample.stop(Timer.builder("mysql.count.duration") .tag("query", extractQueryType(query)) .register(meterRegistry)); } } public void analyzeCostProfile(String query) { jdbcTemplate.execute((ConnectionCallback<Void>) connection -> { try (Statement stmt = connection.createStatement()) { stmt.execute("SET profiling = 1"); // 执行查询 jdbcTemplate.queryForObject(query, Long.class); // 获取profile信息 try (ResultSet rs = stmt.executeQuery("SHOW PROFILE")) { while (rs.next()) { double duration = rs.getDouble("Duration"); if (duration > 0.001) { log.info("步骤: {}, 耗时: {}s", rs.getString("Status"), duration ); } } } } catch (SQLException e) { log.error("Profile分析失败", e); } finally { // 确保关闭profiling try { connection.createStatement().execute("SET profiling = 0"); } catch (SQLException e) { log.warn("关闭profiling失败", e); } } return null; }); } private String extractQueryType(String query) { if (query.contains("COUNT(*)")) return "count_star"; if (query.contains("COUNT(1)")) return "count_one"; if (query.contains("COUNT(id)")) return "count_id"; if (query.contains("COUNT(email)")) return "count_email"; return "count_other"; } } 生产环境实战场景场景 1:高并发计数器实现(使用 Caffeine 缓存) 场景 2:分库分表场景的 COUNT 优化场景 3:COUNT 策略选择场景 4:带熔断器的 COUNT 服务代码高亮:
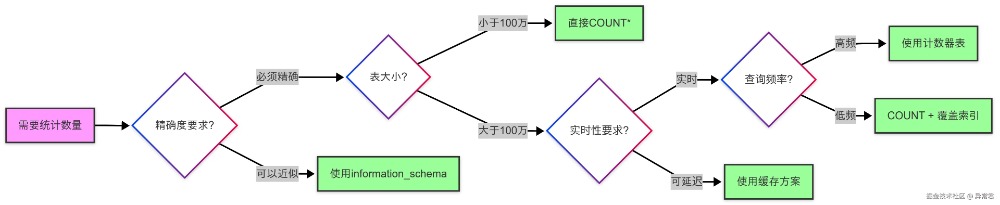
@Component @Slf4j public class CountCircuitBreaker { private final CircuitBreaker circuitBreaker; @Autowired private RedisTemplate<String, Long> redisTemplate; @Autowired private JdbcTemplate jdbcTemplate; public CountCircuitBreaker() { CircuitBreakerConfig config = CircuitBreakerConfig.custom() .failureRateThreshold(50) .waitDurationInOpenState(Duration.ofSeconds(30)) .slidingWindowSize(10) .build(); this.circuitBreaker = CircuitBreaker.of("countService", config); circuitBreaker.getEventPublisher() .onStateTransition(event -> log.warn("熔断器状态变更: {} -> {}", event.getStateTransition().getFromState(), event.getStateTransition().getToState()) ); } public long getCountWithFallback(String tableName, Supplier<Long> countSupplier) { return circuitBreaker.executeSupplier(() -> { log.debug("执行COUNT查询: {}", tableName); return countSupplier.get(); }, throwable -> { log.error("COUNT查询失败,使用降级策略: {}", tableName, throwable); return getFallbackCount(tableName); }); } private long getFallbackCount(String tableName) { // 降级策略优先级 // 1. 尝试从Redis缓存获取 String cacheKey = "count:fallback:" + tableName; Long cached = redisTemplate.opsForValue().get(cacheKey); if (cached != null) { log.info("使用Redis缓存值作为降级: {} = {}", tableName, cached); return cached; } // 2. 使用information_schema近似值 try { String sql = """ SELECT table_rows FROM information_schema.tables WHERE table_schema = DATABASE() AND table_name = ? """; Long approximate = jdbcTemplate.queryForObject(sql, Long.class, tableName); if (approximate != null) { log.info("使用近似值作为降级: {} ≈ {}", tableName, approximate); // 缓存近似值 redisTemplate.opsForValue().set(cacheKey, approximate, Duration.ofMinutes(10)); return approximate; } } catch (Exception e) { log.error("获取近似值失败", e); } // 3. 返回-1表示无法获取 log.warn("所有降级策略失败: {}", tableName); return -1L; } } COUNT 优化配置类MySQL 8.0 新特性对 COUNT 的影响决策流程图
时间复杂度分析 注:n 为表的总行数 最佳实践
总结
参考文章:原文链接 该文章在 2025/12/5 16:27:46 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886